Design Pattern for Unit-Testable Event-Based (SAX) Parsers
Note Some improvements to this article are described in a later blog post. Read this one first, then head on over to the later blog post.
Recently, I’ve been looking a parsing some XML documents using a SAX parser, primarily for the faster speed and smaller memory requirements. But using a SAX parser generally means you need to keep track of state (where you are in in the XML tree).
For simple documents, particularly where data is stored in attributes, keeping track of the state is relatively easy. But, things can get out of hand quickly if there is a mix of character data and attributes, and especially if there are repeated element names in different contexts. Throw in a desire to unit test the code, and things explode.
Strangely, if you search online for design patterns to handle these problems, your search will end with nothing. This problem has been percolating in the back of my mind for the last month: what is the best way to do downstream stream parsing from a SAX parser with complex elements, lots of well-defined hierarchy, an in a way that is trivially easy to unit test? When I started implementing the code, I initially accepted that maybe this wasn’t possible with a SAX parser, but in a moment of genius, my thoughts stumbled on a design pattern that simplified the code, made the parser highly reusable, and easy to unit test with no dependency on the SAX parser. I’m probably not the first to dream up this strategy, but I haven’t seen it online elsewhere, so I’m putting it online here, and maybe elsewhere in the future.
Strategy
The strategy is to manage state through a stack of small XML parsers (mini-parsers) created on demand. Events from the SAX parser are forwarded through the stack of parsers, from the base to the top of the stack. Only the parser at the top of the stack handles the events - the others simply pass along the data. Each mini-parser knows how to parse a small portion of the document, and the stack of mini-parsers automates the task of keeping track of state. Additionally, because the parsers are created on-demand, you can pass to them the appropriate parent object for the objects the parser is creating. Lastly, because each mini-parser is independent, it is easy to hook up unit testing. Graphically, it looks something like the following.
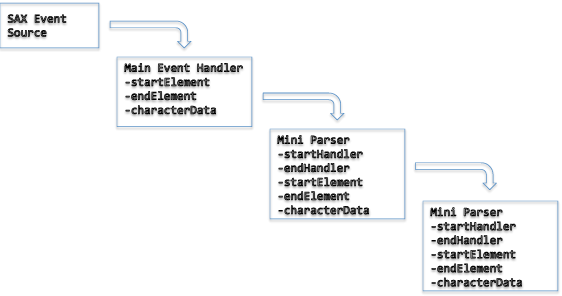
I’ll use an example to explain how this works. Let’s imaging you need to parse the following XML document representing an online order:
<Order>
<CustomerInfo>
<Contact firstName="P" lastName="Sherman"/>
<Address street="42 Wallaby Lane" city="Sydney" country="Australia" />
<PaymentInfo>
<CreditCard number="1234-5678-9012-3456" expiry="01/2020"/>
</PaymentInfo>
</CustomerInfo>
<Items>
<Item itemId="123-456" quantity="1" unitPrice="$100"/>
</Items>
</Order>
In this fictitious sample, there are essentially 3 highly related pieces of data: customer info, payment info, and items. (I’ve intentionally structured it this way as an example - not as the best possible structure.) Each of these will be parsed separately using a mini-parser. These are automatically created by the main parser that registers itself for SAX events.
Let’s assume we have a class OrderParser, and the methods startElement and endElement are registered to handle the relevant SAX events. (To keep things simple, I’m only interested in elements, skipping over character data, but there are obvious extensions.) In C++, the header looks something like:
class OrderParser
{
public:
void startElement(string& elementName, attributeMap& attrs);
void endElement(string& elementName);
private:
size_t _depth; //Initialize to 0
IMiniParser* _miniParser; //Initialize to nullptr
Order* _order; //The order structure we are creating
};
The role of the OrderParser is to pass events down to the correct mini-parser. So what does the mini-parser look like?
class IMiniParser
{
public:
void beginHandler(string& elementName, attributeMap& attrs); //This is called to handle the first set of attributes
void endHandler(); //This is called just before the parser is destroyed (so it can pass of any internal data)
void startElement(string& elementName, attributeMap& attrs);
void endElement(string& elementName);
};
With that covered, let’s look at the implementation of OrderParser. Remember, the job of the main parser is to forward SAX events to the appropriate mini-parser.
void OrderParser::startElement(string& elementName, attributeMap& attrs)
{
++_depth;
if (_depth == 2) //In this case, skip the root element, so start at 2
{
if (elementName.compare("CustomerInfo") == 0)
{
_miniParser = new CustomerInfoMiniParser(_order);
//This and the following line create and initialize the mini parser that
//will handle sub-elements, including the PaymentInfo. Notice that the
//mini-parser gets the _order object, which is where it will add it's
//parsed data
_miniParser->startHandler(elementName, attrs);
}
... //Add appropriate for each type at level of 2
}
else if (_depth > 2)
{
//Forward the event to the mini-parser
_miniParser->startElement(elementName, attrs);
}
}
void OrderParser::endElement(string& elementName)
{
if (_depth == 2)
{
//Once we are back at a depth of 2, then this mini-parser is
//done, so end the parser
_miniParser->endHandler();
delete _miniParser;
_miniParser = nullptr;
}
else if (_depth > 2)
{
//Forward on the event to the mini-parser
_miniParser->endElement(elementName);
}
--_depth;
}
The mini-parsers work in essentially the same way, handling the elements they know about, creating mini-parsers for further sub-elements, and passing the most appropriate parent object (a child of the Order object). For example, the implementation of the CustomerInfoMiniParser would look something like
void CCustomerInfoMiniParser::CCustomerInfoMiniParser(Order* order)
: _owner(order)
{
//We are parsing the customer info into the order parameter
//When unit testing, this may be nullptr
}
void CCustomerInfoMiniParser::~CCustomerInfoMiniParser()
{
//If the owner was set in the constructor, then we will have
//already transferred ownership, otherwise delete the created
//data
delete _contact;
}
void CCustomerInfoMiniParser::beginHandler(string& elementName, attributeMap& attrs)
{
//We have started parsing customer information so create the member
//that will contain the data
++_depth;
_contact = new Contact;
}
void CCustomerInfoMiniParser::endHandler()
{
//We are ending the mini parser, so if _owner is set, transfer
//ownership of the created customer data to the owner. Set the
//value to nullptr to indicate that we have transferred ownership
//If there is no owner, then don't transfer ownership, and just
//wait until the destructor to delete
if (_owner != nullptr)
{
_owner->setContact(_contact);
_contact = nullptr;
}
}
void CustomerInfoMiniParser::startElement(string& elementName, attributeMap& attrs)
{
++_depth;
if (_depth == 2)
{
if (elementName.compare("Contact") == 0)
{
_contact->firstName = attrs.getAttribute("firstName");
_contact->lastName = attrs.getAttribute("lastName");
}
... // Handle other elements
else
{
//If we didn't know what this element is, create a
//null mini-parser to eat the elements (see the next section)
_miniParser = new NullMiniParser();
_miniParser->startHandler(elementName, attrs);
//This is the depth where we need to end the mini-parser
//(see endElement)
_miniParserEndDepth = 2;
}
}
}
void CustomerInfoMiniParser::endElement(string& elementName)
{
//See the next section for details on the null mini-parser
if (_miniParser != nullptr)
{
if (_depth == _miniParserEndDepth)
{
_miniParser->endHandler();
delete _miniParser;
_miniParser = nullptr;
}
else
{
_miniParser->endElement(elementName);
}
}
--_depth;
}
Unknown Elements
One of the challenges of event-based parsers is handling state, particularly if items have the same name. How does the mini-parser pattern handle these? Perhaps surprisingly, unknown elements are trivially handled with a null mini-parser. Then null mini-parser does nothing except eat SAX events until the element and all of it’s children are done. Essentially, we modify all places where we handle start elements adding an else statement for any unknown element. For example, the startElement member in the OrderParser becomes
void OrderParser::startElement(string& elementName, attributeList& attrs)
{
++_depth;
if (_depth == 2) //In this case, skip the root element, so start at 2
{
if (elementName.compare("CustomerInfo") == 0)
{
_miniParser = new CustomerInfoMiniParser(_order);
_miniParser->startHandler(elementName, attrs);
}
else if (...)
{
//Add appropriate else if for each type at level of 2
}
else
{
_miniParser = new NullMiniParser(); //Creates a mini-parser that "eats" all unknown elements
_miniParser->startHandler(elementName, attrs);
}
}
else if (_depth > 2)
{
//Forward the event to the mini-parser. In the case of
//an unknown element, this just goes to the null mini-parser
_miniParser->startElement(elementName, attrs);
}
}
Unit Testing
Event-based parsers can be hard to unit test because you need to put the parser into the correct. This architecture makes it easy to unit test because you can test each mini-parser individually by emulating the events. Construct the mini-parser in your test environment, the call beginHandler, startElement, endElement, endHandler in the expected order. The details will depend on your test environment. A test for the for the CustomerInfoMiniParser might look like
void CustomerInfoMiniParserTest()
{
//Construct attribute maps with appropriate values (you'll need one for
//each faked SAX call)
attributeMap attrsCustomerInfo;
...
//Create the parser we're testing
CustomerInfoMiniParser parser(nullptr);
//Send mock SAX events
parser.beginHandler("CustomerInfo", attrsCustomerInfo);
parser.startElement("Contact", attrsContact);
parser.endElement("Contact");
parser.startElement("Address", attrsAddress);
parser.endElement("Address");
... //Continue sending appropriate events
parser.endHandler();
//Check that the data was constructed correctly
Contact* contact = parser.getContact();
//Unit testing asserts to test the created contact class
}
Final Thoughts
I’ve written the code above to explain the basic concept. Where I’ve implemented this in practice, I use a number of abstract classes to provide most of the implementation. Lastly, if this helped you, leave a comment and let me know (no registration required). Maybe I’ll write this up for CodeProject.